Yep, fair point. I'm a fan of old-school forums myself, like phpBB.
That depends on your CPU, hardware and workloads.
You're probably thinking of Intel and AVX512 (x86-64-v4) in which case, yes it's pointless because Intel screwed up the implementation, but on the other hand, that's not the case for AMD. Of course, that assumes your program actually makes use of AVX512. v3 is worth it though.
In any case, the usual places where you'd see improvements is when you're compiling stuff, compression, encryption and audio/video encoding (ofc, if your codec is accelerated by your hardware, that's a moot point). Sometimes the improvements are not apparent by normal benchmarks, but would have an overall impact - for instance, if you use filesystem compression, with the optimisations it means you now have lower I/O latency, and so on.
More importantly, if you're a laptop user, this could mean better battery life since using more efficient instructions, so certain stuff that might've taken 4 CPU cycles could be done in 2 etc.
In my own experience on both my Zen 2 and Zen 4 machines, v3/v4 packages made a visible difference. And that's not really surprising, because if you take a look the instructions you're missing out on, you'd be like 'wtf':
CMPXCHG16B, LAHF-SAHF, POPCNT, SSE3, SSE4_1, SSE4_2, SSSE3, AVX, AVX2, BMI1, BMI2, F16C, FMA, LZCNT, MOVBE, OSXSAVE.
And this is not counting any of the AVX512 instructions in v4, or all the CPU-specific instructions eg in znver4.
It really doesn't make sense that you're spending so much money buying a fancy CPU, but not making use of half of its features...
No need to hop around for the same thing.
It's not really the same thing. EndeavourOS is basically vanilla Arch + a few branding packages. CachyOS is an opionated Arch with optimised packages.
You still have the option to select the DE and the packages you want to install - just like EndeavourOS - but what sets Cachy apart is the optimisations. For starters, they have multiple custom kernel options, with the BORE scheduler (and a few others), LTO options etc. Then they also have packages compiled for the x86-64-v3 and v4 architectures for better performance.
Of course, you could also just use Arch (or EndeavourOS) and install the x86-64-v3/v4 packages yourself from ALHP (or even the Cachy repos), and you can even manually install the Cachy kernel or a similar optimised one like Xanmod. But you don't get the custom configs / opinionated stuff. Which you many actually not want as a veteran user. But if you're a newbie, then having those opinionated configs isn't such a bad idea, especially if you decide to just get a WM instead of a DE.
I've been thru all of the above scenarios, depending on the situation. My homelab is vanilla Arch but with packages from the Cachy repo. I've also got a pure Cachy install on my gaming desktop just because I was feeling lazy and just wanted an optimised install quickly. They also have a gaming meta package that installs Steam and all the necessary 32-bit libs and stuff, which is nice.
Then there's Cachy Browser, which is a fork of LibreWolf with performance optimisations (kinda similar to Mercury browser, except Mercury isn't MARCH optimised).
As for support, their Discord is pretty active, you can actually chat with the developers directly, and they're pretty friendly (and this includes Piotr Gorski, the main dev, and firelzrd - the person behind the BORE scheduler). Chatting with them, I find the quality of technical discussions a LOT higher than the Arch Discord, which is very off-topic and spammy most of the time.
Also, I liked their response to Arch changes and incidents. When Arch made the recent mkinitcpio changes, their made a very thorough announcement with the exact steps you needed to take (which was far more detailed than the official Arch announcement). Also, when the xz backdoor happened, they updated their repos to fix it even before Arch did.
I've also interacted with the devs pesonally with various technical topics - such as CFLAG and MARCH optimisations, performance benchmarking etc, and it seems like they definitely know their stuff.
So I've full confidence in their technical ability, and I'm happy to recommend the distro for folks interested in performance tuning.
cc: @governorkeagan@lemdro.id
16c/64gb Zen4 system here with optimised packages and kernel. I still care about bloat. Not from a performance reason obviously, but from a systems management / updates / attack surface point of view. Fewer packages == fewer breakages == fewer headaches.
https://www.freewear.org/ - They support several opensource projects, so there's a good chance your favorite project is also there.
Same with https://www.hellotux.com/ - but unlike others, they embroider their logos instead of just printing them - as a result, they look "official" and last longer.
For future reference - in case you want to order something over $1000: I recently bought a PC directly from a small manufacturer's website (not your usual Amazon etc) which was over $1000 NZD, and I didn't get charged any duties for it. I'm not a 100% sure why, but it could be that didn't declare the full value on the waybill. And it also got shipped by DHL, who'd normally take care of clearing the customs duties etc and would contact you if you had to pay anything.
But on the other hand, if I'd ordered it via Amazon or eBay, I would've definitely had to pay duties. For instance, a couple of years ago, I had ordered another PC - this was from eBay - and they shipped it via DHL. Normally if the seller used the eBay Global Shipping option, eBay would've calculated and charged me the duties during checkout itself. In this case however, DHL handled it. I also had to apply for a client number with customs beforehand, since I was importing something over $1000 (this was basically just filing out a form and providing identification). But this can take a couple of weeks, so best to get registered well in advance, so as to not hold up the delivery.
So maybe what Dave implied was true (as in they keep any eye out only for the big name exporters).
Hmm, are you really using PulseAudio, or is it actually PipeWire?
If it's the former, I'd recommend getting rid of all PulseAudio packages first, and then switch to PipeWire by installing the following packages: pipewire pipewire-audio pipewire-pulse wireplumber. Then enable and start the necessary services and test (maybe reboot for good measure).
The Arch Wiki covers all the details. On a normal system, you shouldn't need to do any special config besides enabling the services.
Discordo is a completely open-source frontend, and it's a native TUI app written 100% in Go - no Electron/HTML/Javascript crap.
If you want a GUI app and something not so barebones, there's Dissent - a GTK4 app, also written in Go, with no Electron/HTML/Javascript crap.
And if you're a Qt fan, there's also QTCord, written in Python.
cc: @powermaker450@discuss.tchncs.de
Yes, Zellij runs on top of bash/fish etc, no need to change your existing shell. And yes, you can control with your mouse as well, but you can't resize the panes with your mouse - but other than that, most mouse operations work as you'd expect.
Others here have already given you some good overviews, so instead I'll expand a bit more on the compilation part of your question.
As you know, computers are digital devices - that means they work on a binary system, using 1s and 0s. But what does this actually mean?
Logically, a 0 represents "off" and 1 means "on". At the electronics level, 0s may be represented by a low voltage signal (typically between 0-0.5V) and 1s are represented by a high voltage signal (typically between 2.7-5V). Note that the actual voltage levels, or what is used to representation a bit, may vary depending on the system. For instance, traditional hard drives use magnetic regions on the surface of a platter to represent these 1s and 0s - if the region is magnetized with the north pole facing up, it represents a 1. If the south pole is facing up, it represents a 0. SSDs, which employ flash memory, uses cells which can trap electrons, where a charged state represents a 0 and discharged state represents a 1.
Why is all this relevant you ask?
Because at the heart of a computer, or any "digital" device - and what sets apart a digital device from any random electrical equipment - is transistors. They are tiny semiconductor components, that can amplify a signal, or act as a switch.
![]()
A voltage or current applied to one pair of the transistor's terminals controls the current through another pair of terminals. This resultant output represents a binary bit: it's a "1" if current passes through, or a "0" if current doesn't pass through. By connecting a few transistors together, you can form logic gates that can perform simple math like addition and multiplication. Connect a bunch of those and you can perform more/complex math. Connect thousands or more of those and you get a CPU. The first Intel CPU, the Intel 4004, consisted of 2,300 transistors. A modern CPU that you may find in your PC consists of hundreds of billions of transistors. Special CPUs used for machine learning etc may even contain trillions of transistors!
Now to pass on information and commands to these digital systems, we need to convert our human numbers and language to binary (1s and 0s), because deep down that's the language they understand. For instance, in the word "Hi", "H", in binary, using the ASCII system, is converted to 01001000 and the letter "i" would be 01101001. For programmers, working on binary would be quite tedious to work with, so we came up with a shortform - the hexadecimal system - to represent these binary bytes. So in hex, "Hi" would be represented as 48 69, and "Hi World" would be 48 69 20 57 6F 72 6C 64. This makes it a lot easier to work with, when we are debugging programs using a hex editor.
Now suppose we have a program that prints "Hi World" to the screen, in the compiled machine language format, it may look like this (in a hex editor):
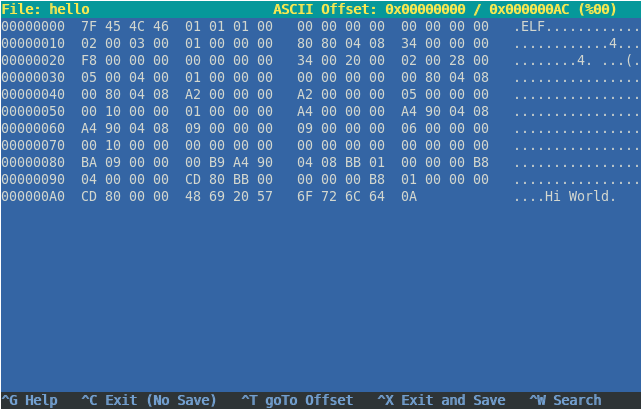
As you can see, the middle column contains a bunch of hex numbers, which is basically a mix of instructions ("hey CPU, print this message") and data ("Hi World").
Now although the hex code is easier for us humans to work with compared to binary, it's still quite tedious - which is why we have programming languages, which allows us to write programs which we humans can easily understand.
If we were to use Assembly language as an example - a language which is close to machine language - it would look like this:
SECTION .data
msg: db "Hi World",10
len: equ $-msg
SECTION .text
global main
main:
mov edx,len
mov ecx,msg
mov ebx,1
mov eax,4
int 0x80
mov ebx,0
mov eax,1
int 0x80
As you can see, the above code is still pretty hard to understand and tedious to work with. Which is why we've invented high-level programming languages, such as C, C++ etc.
So if we rewrite this code in the C language, it would look like this:
#include <stdio.h>
int main() {
printf ("Hi World\n");
return 0;
}
As you can see, that's much more easier to understand than assembly, and takes less work to type! But now we have a problem - that is, our CPU cannot understand this code. So we'll need to convert it into machine language - and this is what we call compiling.
Using the previous assembly language example, we can compile our assembly code (in the file hello.asm), using the following (simplified) commands:
$ nasm -f elf hello.asm
$ gcc -o hello hello.o
Compilation is actually is a multi-step process, and may involve multiple tools, depending on the language/compilers we use. In our example, we're using the nasm assembler, which first parses and converts assembly instructions (in hello.asm) into machine code, handling symbolic names and generating an object file (hello.o) with binary code, memory addresses and other instructions. The linker (gcc) then merges the object files (if there are multiple files), resolves symbol references, and arranges the data and instructions, according to the Linux ELF format. This results in a single binary executable (hello) that contains all necessary binary code and metadata for execution on Linux.
If you understand assembly language, you can see how our instructions get converted, using a hex viewer:

So when you run this executable using ./hello, the instructions and data, in the form of machine code, will be passed on to the CPU by the operating system, which will then execute it and eventually print Hi World to the screen.
Now naturally, users don't want to do this tedious compilation process themselves, also, some programmers/companies may not want to reveal their code - so most users never look at the code, and just use the binary programs directly.
In the Linux/opensource world, we have the concept of FOSS (free software), which encourages sharing of source code, so that programmers all around the world can benefit from each other, build upon, and improve the code - which is how Linux grew to where it is today, thanks to the sharing and collaboration of code by thousands of developers across the world. Which is why most programs for Linux are available to download in both binary as well as source code formats (with the source code typically available on a git repository like github, or as a single compressed archive (.tar.gz)).
But when a particular program isn't available in a binary format, you'll need to compile it from the source code. Doing this is a pretty common practice for projects that are still in-development - say you want to run the latest Mesa graphics driver, which may contain bug fixes or some performance improvements that you're interested in - you would then download the source code and compile it yourself.
Another scenario is maybe you might want a program to be optimised specifically for your CPU for the best performance - in which case, you would compile the code yourself, instead of using a generic binary provided by the programmer. And some Linux distributions, such as CachyOS, provide multiple versions of such pre-optimized binaries, so that you don't need to compile it yourself. So if you're interested in performance, look into the topic of CPU microarchitectures and CFLAGS.
Sources for examples above: http://timelessname.com/elfbin/
It's still being maintained. It's a third-party project btw, but it's just a patchset so you'll need to build it yourself: https://github.com/cyberus-technology/virtualbox-kvm
Arch users can also install the virtualbox-kvm package from AUR to get it all in one go, nice and easy.
If you're already on Arch/EOS, you don't need to "move distros", all you need to do (ish) is to update your pacman.conf with Cachy's repos and run a
pacman -Syuuto reinstall your packages. Oh, and you might also want to install the cachy kernel and maybe the browser for the full experience. Your files and config will remain the same, unless you plan to update/merge them - in which case, I'd recommend replacing your makepkg.conf with the one Cachy provides, for the optimised compiler flags. Other than that, there's no significant difference between the default configs and Cachy's. In fact, EndeavourOS actually deviates more since it uses dracut for generating the initrd, whereas Cachy, like Arch, defaults to mkinitcpio.Anyways, there's not much point trying CachyOS in a VM since it's really not that much different from EndeavourOS (from a UX point of view); the whole point of Cachy is to eke out the best performance from your system, so running it in a VM defeats the purpose.